728x90
반응형
- 데이터 평균:

- 데이터 표준 편차:

- 표준화:
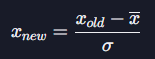
실습:
from sklearn import preprocessing
import pandas as pd
import numpy as np
NBA_FILE_PATH = '../datasets/NBA_player_of_the_week.csv'
# 소수점 5번째 자리까지만 출력되도록 설정
pd.set_option('display.float_format', lambda x: '%.5f' % x)
nba_player_of_the_week_df = pd.read_csv(NBA_FILE_PATH)
height_weight_age_df = nba_player_of_the_week_df[['Height CM', 'Weight KG', 'Age']]
# 데이터를 standardize 함
scaler = preprocessing.StandardScaler()
standardized_data = scaler.fit_transform(height_weight_age_df)
standardized_df = pd.DataFrame(standardized_data, columns=['Height', 'Weight', 'Age'])

728x90
반응형
'이론공부 > 머신러닝' 카테고리의 다른 글
| 머신러닝 모델 예측 값 저하 원인 (0) | 2024.04.09 |
|---|---|
| 데이터 전처리: one-hot encoding (0) | 2024.04.09 |
| 앙상블: 에다부스트 (0) | 2024.04.08 |
| 데이터 전처리: feature scaling (0) | 2024.04.04 |
| 앙상블-결정트리, bagging (RandomForest), boosting (Adaboost) (0) | 2024.04.03 |