- 장점:
데이터를 분류하는 방법이 직관적
쉽게 해석 가능(feature importance)

- 지니 불순도(gini impurity)
결정트리에서 분류에 대한 기준(손실함수)- 결정트리의 질문을 정하는데 사용됨
= 각 노드의 데이터 셋안에 서로 다른 분류들이 얼마나 섞여있는지
(불순도 보고 질문이 분류를 잘하는 질문인지 파악 가능)



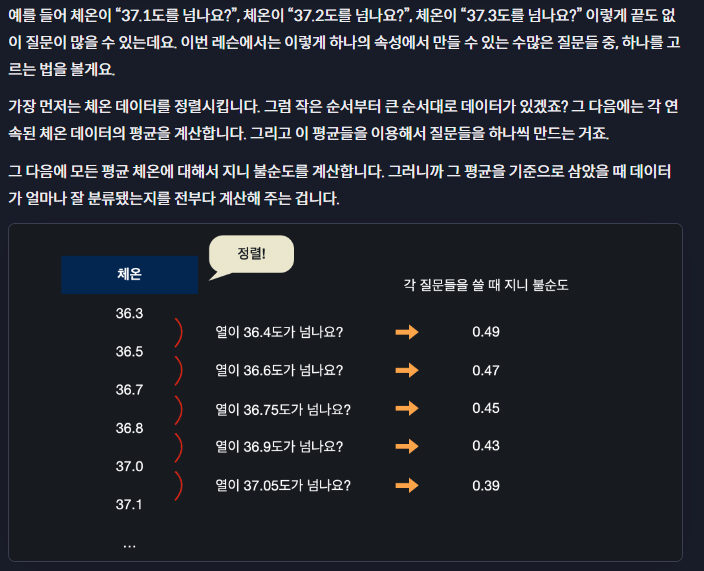
- 질문에 대한 지니불순도 구하기



- 질문이 숫자형으로 구성될 때
- Feature importance
- node importance: 한 개 노드의 중요도
한 노드에서 데이터를 두개로 나눴을 때(위 노드에서 아래 노드로 내려오면서, 데이터 수에 비례해서 불순도가 얼마나 줄어들었는지(= 정보 증가량, information gain)



ex.

=>

- 실습
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
import pandas as pd
# 데이터 셋 불러 오기
cancer_data = load_breast_cancer()
# 저번 과제에서 쓴 데이터 준비 코드를 갖고 오세요
X = pd.DataFrame(cancer_data.data, columns=cancer_data.feature_names)
y = pd.DataFrame(cancer_data.target, columns=['class'])
X_train, X_test, y_train, y_test = train_test_split(X,y, test_size=0.2, random_state=5)
y_train = y_train.values.ravel() # 향후 모델을 학습시킬 때 경고 메시지가 나오지 않게
# 여기에 코드를 작성하세요
model = DecisionTreeClassifier(max_depth=5,random_state=42)
model.fit(X_train,y_train)
predictions = model.predict(X_test)
score = model.score(X_test,y_test)
# 테스트 코드
predictions, score
'이론공부 > 머신러닝' 카테고리의 다른 글
| 데이터 전처리: feature scaling (0) | 2024.04.04 |
|---|---|
| 앙상블-결정트리, bagging (RandomForest), boosting (Adaboost) (0) | 2024.04.03 |
| LASSO, grid search (0) | 2024.04.01 |
| k_fold_score (0) | 2024.04.01 |
| Multi-Arm Bandit (0) | 2023.04.03 |