- 과소적합의 경우
: 충분히 복잡한 모델 사용하기
(많은 굴곡 이용해서 함수가 train 데이터셋 최대한 많이 통과)

but, 단순히 복잡한 모델을 이용해서 학습하는 경우 과적합 가능성 높음
실습:
다항회귀모델 학습 시키기
from sklearn.preprocessing import PolynmialFeatures
polynomial_transformer = PolynomialFeatures(6) # 6차항의 다항회귀 모델 사용
polynomial_features = polynomial_transformer.fit_transform(X.values)
features = polynomial_transformer.get_feature_names(X.columns)
X = pd.DataFrame( polynomial_features, columns=features)


- 복잡 모델 + 과적합 방지 방법
: 정규화
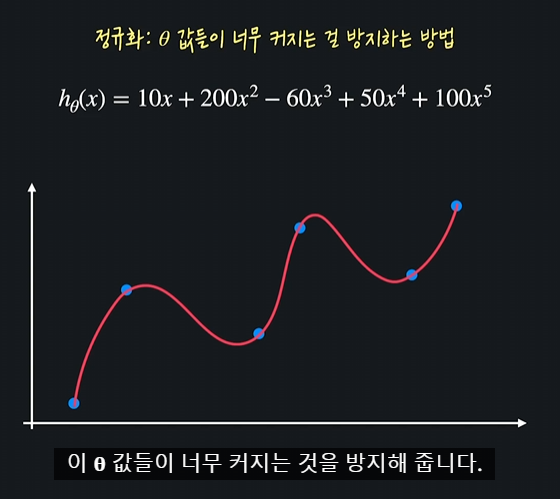
- 정규화: 가설함수의 theta값들이 너무 커지는 것을 방지하여 과적합을 예방하는 방법
손실함수에 정규화 항을 더해서 theta값들이 커지는 것을 방지함

정규화는 모델의 파라미터 (즉 학습을 통해 찾고자 하는 값들 - 회귀의 경우 )에 대한 손실 함수를 최소화 하는 모든 알고리즘에 적용할 수 있습니다. 따라서 다중 회귀, (다중) 다항 회귀, 로지스틱 회귀 모델 모두에 정규화를 적용할 수 있는데요. 그냥 모델에 해당하는

ex. Logistic Regression
실습)
LogisticRegression(penalty='none') # 정규화 사용 안함
LogisticRegression(penalty='l1') # L1 정규화 사용
LogisticRegression(penalty='l2') # L2 정규화 사용
LogisticRegression() # 위와 똑같음: L2 정규화 사용

1) L1 정규화(Lasso Regression, Lasso 모델):

- 실습
from sklearn.linear_model import Lasso

(alpha: lambda value, max_iter: 경사하강 최대 몇 번, normalization: 피쳐 스케일링 0~1)
from sklearn.linear_model import Lasso
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
from sklearn.preprocessing import PolynomialFeatures
from math import sqrt
import numpy as np
import pandas as pd
# 데이터 파일 경로 정의
INSURANCE_FILE_PATH = './datasets/insurance.csv'
insurance_df = pd.read_csv(INSURANCE_FILE_PATH) # 데이터를 pandas dataframe으로 갖고 온다 (insurance_df.head()를 사용해서 데이터를 한 번 살펴보세요!)
insurance_df = pd.get_dummies(data=insurance_df, columns=['sex', 'smoker', 'region']) # 필요한 열들에 One-hot Encoding을 해준다
# 입력 변수 데이터를 따로 새로운 dataframe에 저장
X = insurance_df.drop(['charges'], axis=1)
polynomial_transformer = PolynomialFeatures(4) # 4 차항 변형기를 정의
polynomial_features = polynomial_transformer.fit_transform(X.values) # 4차 항 변수로 변환
features = polynomial_transformer.get_feature_names(X.columns) # 새로운 변수 이름들 생성
X = pd.DataFrame(polynomial_features, columns=features) # 다항 입력 변수를 dataframe으로 만들어 준다
y = insurance_df[['charges']] # 목표 변수 정의
# 여기에 코드를 작성하세요
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size=0.3, random_state=5)
model = Lasso(alpha=1, max_iter=2000, normalize=True)
model.fit(X_train,y_train)
y_train_predict = model.predict(X_train)
y_test_predict = model.predict(X_test)
# 테스트 코드
mse = mean_squared_error(y_train, y_train_predict)
print("training set에서 성능")
print("-----------------------")
print(f'오차: {sqrt(mse)}')
mse = mean_squared_error(y_test, y_test_predict)
print("testing set에서 성능")
print("-----------------------")
print(f'오차: {sqrt(mse)}')
2) L2 정규화(Ridge Regression, Ridge 모델):

- 실습
from sklearn.linear_model import Ridge
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
from sklearn.preprocessing import PolynomialFeatures
from math import sqrt
import numpy as np
import pandas as pd
INSURANCE_FILE_PATH = './datasets/insurance.csv'
insurance_df = pd.read_csv(INSURANCE_FILE_PATH)
insurance_df = pd.get_dummies(data=insurance_df, columns=['sex', 'smoker', 'region'])
# 기존 데이터에서 입력 변수 데이터를 따로 저장한다
X = insurance_df.drop(['charges'], axis=1)
polynomial_transformer = PolynomialFeatures(4) # 4 차항 변형기를 정의한다
polynomial_features = polynomial_transformer.fit_transform(X.values) # 데이터 6차 항 변수로 바꿔준다
features = polynomial_transformer.get_feature_names(X.columns) # 변수 이름들도 바꿔준다
# 새롭게 만든 다항 입력 변수를 dataframe으로 만들어 준다
X = pd.DataFrame(polynomial_features, columns=features)
y = insurance_df[['charges']]
# 여기에 코드를 작성하세요
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size=0.3, random_state=5)
model = Ridge(alpha=0.01, max_iter=2000, normalize=True)
model.fit(X_train,y_train)
y_train_predict = model.predict(X_train)
y_test_predict = model.predict(X_test)
# 테스트 코드
mse = mean_squared_error(y_train, y_train_predict)
print("training set에서 성능")
print("-----------------------")
print(f'오차: {sqrt(mse)}')
mse = mean_squared_error(y_test, y_test_predict)
print("testing set에서 성능")
print("-----------------------")
print(f'오차: {sqrt(mse)}')
'이론공부 > 머신러닝' 카테고리의 다른 글
| Gaussian Process Regression(GPR), Bayesian Optimization(BO) (0) | 2024.06.14 |
|---|---|
| L1, L2 정규화 차이점 (0) | 2024.04.09 |
| 머신러닝 모델 예측 값 저하 원인 (0) | 2024.04.09 |
| 데이터 전처리: one-hot encoding (0) | 2024.04.09 |
| 데이터 전처리: standardization (0) | 2024.04.09 |