정리 잘 된 참고 블로그가 있어서 태그: https://data-minggeul.tistory.com/11
f1-score 종류와 의미 (macro, weighted, micro)
scikit-learn 의 classification_report 는 분류 모델의 예측 성능을 평가하기 위해 널리 활용된다. 이진 분류일 때는 주로 소수의 클래스에 해당하는 precision, recall, f1-score 를 중요하게 본다. 그래서 함께
data-minggeul.tistory.com
F1 score를 계산하는 데는 Micro F1 외에도 Macro F1과 Weighted F1 같은 다른 방법들이 있습니다. 각 방법은 데이터의 특성과 평가의 목적에 따라 선택하여 사용할 수 있습니다.
1. Macro F1 Score
- **Macro F1 Score**는 각 클래스에 대한 F1 score를 단순히 평균내어 계산합니다. 이 방법은 모든 클래스를 동일한 중요도로 취급하여 각 클래스의 F1 score를 구한 뒤, 그 평균값을 최종 F1 score로 사용합니다. 클래스 간 샘플 수의 불균형이 있을 경우, 샘플 수가 적은 클래스의 성능 변화가 전체 성능 지표에 미치는 영향이 커질 수 있습니다.
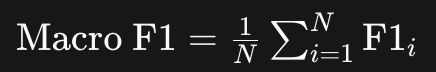
여기서 \(N\)은 클래스의 수이고, \(\text{F1}_i\)는 각 클래스 \(i\)에 대한 F1 score입니다.
2. Weighted F1 Score
- **Weighted F1 Score**는 각 클래스의 샘플 수에 따라 가중치를 부여하여 F1 score를 평균냅니다. 이 방법은 데이터셋 내에서 클래스의 분포가 불균형할 때 유용하며, 각 클래스의 샘플 수를 고려하여 성능을 평가합니다. 즉, 샘플 수가 많은 클래스의 성능이 전체 평가에 더 큰 영향을 미칩니다.

여기서 \(w_i\)는 클래스 \(i\)의 샘플 수에 따른 가중치이고, \(N\)은 클래스의 수, \(\text{F1}_i\)는 각 클래스 \(i\)에 대한 F1 score입니다.
3. Micro F1 Score
Micro F1 score는 분류 문제에서 성능을 평가하는 지표 중 하나입니다. 특히, 클래스(레이블)의 분포가 불균형할 때 유용하게 사용됩니다. Micro F1 score는 전체 데이터셋에 대한 정밀도(Precision)와 재현율(Recall)을 계산한 뒤, 이 두 값의 조화 평균을 구해 계산됩니다.
정밀도는 모델이 True로 예측한 것 중 실제 True인 것의 비율을, 재현율은 실제 True인 것 중 모델이 True로 예측한 것의 비율을 의미합니다. Micro F1 score는 모든 클래스에 대해 True Positive, False Positive, False Negative 값을 합산하여 계산하기 때문에, 각 클래스의 샘플 수가 불균등할 때 각 클래스를 공평하게 다루는 성능 지표로 사용됩니다.
계산 공식은 다음과 같습니다:
1. **Micro-averaged Precision** = (Σ True Positive) / (Σ True Positive + Σ False Positive)
2. **Micro-averaged Recall** = (Σ True Positive) / (Σ True Positive + Σ False Negative)
여기서 Σ는 모든 클래스에 대해 합을 의미합니다.
3. **Micro F1 Score** = 2 * (Micro Precision * Micro Recall) / (Micro Precision + Micro Recall)
이처럼, Micro F1 score는 다중 클래스 분류 문제에서 각 클래스의 샘플 수 차이를 고려하여 전체 모델의 성능을 평가할 때 사용됩니다.
- 비교
- **Micro F1 Score**는 전체 모델의 성능을 평가하는 데 초점을 맞추며, 클래스 간 샘플 수의 불균형을 고려합니다.
- **Macro F1 Score**는 모든 클래스를 동일한 중요도로 평가하며, 샘플 수의 불균형이 평가에 큰 영향을 줄 수 있습니다.
- **Weighted F1 Score**는 각 클래스의 중요도를 샘플 수에 따라 가중치를 두어 평가하며, 불균형한 데이터셋에서 각 클래스의 영향력을 조정합니다.
선택하는 F1 score 방식은 분석하려는 데이터의 특성과 평가의 목적에 따라 달라질 수 있습니다.
Micro F1 Score와 Macro F1 Score는 둘 다 다중 클래스 분류 문제에서 모델의 성능을 평가하는 데 사용되는 지표입니다. 그러나 계산 방식과 각각이 초점을 맞추는 부분에서 차이가 있습니다.
### Micro F1 Score
- **Micro F1 Score**는 전체 데이터셋에 대한 성능을 하나의 집합으로 보고 계산합니다. 이 방식에서는 모든 클래스의 True Positive, False Positive, False Negative 값을 합산하여 전체 데이터셋에 대한 정밀도(Precision)와 재현율(Recall)을 계산한 뒤, 이를 기반으로 F1 Score를 도출합니다. 이 접근법은 모든 클래스를 통틀어 성능을 평가하기 때문에, 각 클래스의 샘플 수가 불균형한 경우에도 공정한 평가가 가능합니다.

### Macro F1 Score
- **Macro F1 Score**는 각 클래스에 대한 F1 Score를 개별적으로 계산한 후, 이들의 단순 산술 평균을 취하여 도출합니다. 이 방식에서는 모든 클래스가 동등하게 중요하다고 가정하며, 샘플 수의 불균형이 평가 결과에 직접적인 영향을 주지 않습니다. 즉, 샘플 수가 매우 적은 클래스와 샘플 수가 많은 클래스의 성능이 평가에서 동일한 비중을 갖습니다.

여기서 \(N\)은 클래스의 수이고, \(\text{F1}_i\)는 각 클래스 \(i\)에 대한 F1 score입니다.
### 차이점
- **집계 방식**: Micro F1은 전체 데이터셋을 대상으로 성능을 집계하는 반면, Macro F1은 각 클래스별 성능을 개별적으로 평가한 후 평균을 낸다.
- **클래스 불균형 대응**: Micro F1은 클래스 간 샘플 수의 불균형을 자연스럽게 고려하며, Macro F1은 모든 클래스를 동등하게 취급하여 샘플 수 불균형이 결과에 직접적으로 반영되지 않는다.
- **적용 상황**: Micro F1은 전체적인 성능 평가가 중요하거나 클래스 간 샘플 수가 크게 다를 때 유리하고, Macro F1은 모든 클래스를 공평하게 평가하고자 할 때 유리하다.
따라서 두 지표는 각각 다른 상황과 목적에 맞게 선택하여 사용됩니다.
'이론공부 > 주워들은 컴공' 카테고리의 다른 글
| 시간복잡도 (0) | 2024.04.15 |
|---|---|
| 컴퓨터 (0) | 2024.03.13 |
| 중첩함수 (0) | 2024.01.28 |
| 자료구조: overall (0) | 2023.01.31 |
| 자료구조: 스택(Stack) (0) | 2023.01.26 |